Kafka Schema Registry and JSON Schema: A Comprehensive Guide

Kafka Schema Registry and JSON Schema: A Comprehensive Guide
Introduction
What is Kafka?
Kafka is a distributed streaming platform designed for high throughput and low latency, widely used for:
- Event-driven architectures
- Real-time analytics
- Data pipelines
Kafka Schema Registry: Core Concept
Kafka Schema Registry is a centralized service that:
- Manages and validates message schemas in Kafka topics
- Provides schema versioning
- Ensures compatibility between producers and consumers
The Role of JSON Schema
JSON Schema is a declarative language for:
- Defining JSON data structures
- Enforcing data validation rules
- Ensuring consistent data across distributed systems
Schema Evolution and Compatibility
Types of Schema Compatibility
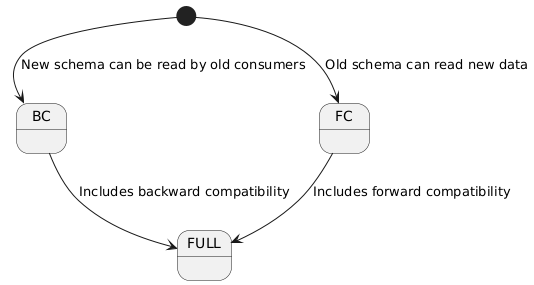
Compatibility Types Explained
- Backward Compatibility:
- New schema versions can be read by consumers using older schemas
- Allows adding new fields
- Existing consumers can still process messages
- Forward Compatibility:
- Old schema versions can consume data from new schemas
- Allows removing fields carefully
- New consumers can process older message formats
- Full Compatibility:
- Combines backward and forward compatibility
- Provides maximum flexibility in schema evolution
Schema Evolution Scenarios
Scenario 1: Making a Field Nullable
One common schema evolution approach is making a field nullable. This allows the field to either contain a value or be absent (null).
Initial Schema (Version 1):
1
2
3
4
5
6
7
8
9
{
"type": "object",
"properties": {
"user_id": { "type": "integer" },
"name": { "type": "string" },
"email": { "type": "string" }
},
"required": ["user_id", "name", "email"]
}
Evolved Schema (Version 2):
1
2
3
4
5
6
7
8
9
10
11
{
"type": "object",
"properties": {
"user_id": { "type": "integer" },
"name": { "type": "string" },
"email": {
"type": ["string", "null"]
}
},
"required": ["user_id", "name"]
}
In this evolution:
- The
emailfield becomes optional emailcan now be a string or null- Maintains compatibility with existing consumers
Scenario 2: Using Default Values
Default values provide a powerful mechanism for maintaining compatibility during schema changes, especially when making breaking changes like converting a nullable field to a required field.
Schema with Default Value:
1
2
3
4
5
6
7
8
9
10
11
{
"type": "record",
"name": "User",
"fields": [
{
"name": "fieldA",
"type": "string",
"default": "default_value"
}
]
}
Benefits of default values:
- Prevent serialization errors
- Maintain backward and forward compatibility
- Ensure smooth data flow during schema changes
Data Flow in Kafka with Schema Registry
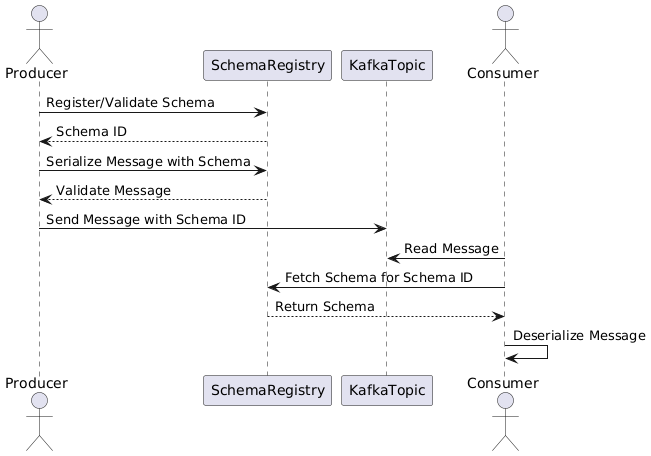
Data Flow Steps
- Producer Side:
- Retrieves or registers schema
- Serializes message using schema
- Sends message with schema ID to Kafka topic
- Kafka Topic:
- Stores messages with schema ID references
- Supports multiple schema versions
- Consumer Side:
- Reads message with schema ID
- Retrieves corresponding schema
- Deserializes message using schema
Practical Implementation
Docker Compose Setup
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- "2181:2181"
schema-registry:
image: confluentinc/cp-schema-registry:7.8.0
hostname: schema-registry
depends_on:
- kafka-broker-1
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: 'zookeeper:2181'
SCHEMA_REGISTRY_LISTENERS: http://schema-registry:8081
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: PLAINTEXT://kafka-broker-1:9092,PLAINTEXT_INTERNAL://localhost:19092
SCHEMA_REGISTRY_DEBUG: 'true'
kafka-broker-1:
image: confluentinc/cp-kafka:latest
hostname: kafka-broker-1
ports:
- "19092:19092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-1:9092,PLAINTEXT_INTERNAL://localhost:19092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
Schema Registry API
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Register a new schema
curl --request POST \
--url http://localhost:8081/subjects/user-registration-test-value/versions \
--header 'Content-Type: application/vnd.schemaregistry.v1+json' \
--data '{
"schemaType": "JSON",
"schema": "{ \"$schema\": \"http://json-schema.org/draft-07/schema#\", \"title\": \"User\", \"description\": \"Schema representing a user\", \"type\": \"object\", \"additionalProperties\": false, \"properties\": { \"name\": { \"type\": \"string\", \"description\": \"Name of person.\" }, \"email\": { \"type\": \"string\", \"description\": \"email of person.\" }, \"userId\": { \"type\": \"string\", \"description\": \"user id in the system\" } }, \"required\": [\"name\", \"userId\", \"email\"] }"
}'
# Fetch Schema
curl --request GET \
--url http://localhost:8081/subjects/user-registration-test-value/versions/latest
# Delete Schema
curl --request DELETE \
--url http://localhost:8081/subjects/user-registration-test-value
Java Integration Examples
Configuration
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
plugins {
id 'java'
id 'org.springframework.boot' version '3.4.0'
id 'io.spring.dependency-management' version '1.1.6'
}
group = 'dev.pravin'
version = '0.0.1-SNAPSHOT'
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
repositories {
mavenCentral()
maven {
url "https://packages.confluent.io/maven"
}
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.kafka:spring-kafka'
implementation 'io.confluent:kafka-json-schema-serializer:7.8.0'
implementation 'io.confluent:kafka-schema-registry-client:7.8.0'
implementation 'org.projectlombok:lombok:1.18.36'
annotationProcessor 'org.projectlombok:lombok:1.18.36'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.kafka:spring-kafka-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
tasks.named('test') {
useJUnitPlatform()
}
1
2
3
spring.application.name=schema registry demo
server.port=8100
spring.kafka.properties.use.latest.version=true
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
@EnableKafka
@Configuration
public class KafkaConfig {
public static final String BROKER_URL = "localhost:19092";
public static final String SCHEMA_REGISTRY_URL = "http://localhost:8081";
public static final String SPRING_KAFKA_ADMIN_CLIENT = "spring-kafka-admin-client";
public static final String GROUP_ID = "group_id_23";
@Bean
public ProducerFactory<String, UserRegistrationTest> producerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_URL);
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaJsonSchemaSerializer.class);
config.put("schema.registry.url", SCHEMA_REGISTRY_URL);
return new DefaultKafkaProducerFactory<>(config);
}
@Bean
public KafkaTemplate<String, UserRegistrationTest> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean
public SchemaRegistryClient schemaRegistryClient() throws RestClientException, IOException {
CachedSchemaRegistryClient client = new CachedSchemaRegistryClient(SCHEMA_REGISTRY_URL, 1);
String jsonString = """
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "User",
"description": "Schema representing a user",
"type": "object",
"additionalProperties": false,
"properties": {
"name": {
"type": "string",
"description": "Name of person."
},
"email": {
"type": "string",
"description": "email of person."
},
"userId": {
"type": "string",
"description": "user id in the system"
}
},
"required": ["name", "userId", "email"]
}
""";
client.register("user-registration-test-value", new JsonSchema(jsonString));
return client;
}
@Bean
public ConsumerFactory<String, UserRegistrationTest> consumerFactory(SchemaRegistryClient schemaRegistryClient) {
Map<String, Object> config = new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_URL);
config.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaJsonSchemaDeserializer.class);
config.put("schema.registry.url", SCHEMA_REGISTRY_URL);
config.put("specific.json.reader", true);
return new DefaultKafkaConsumerFactory<>(config, new StringDeserializer(),
new KafkaJsonSchemaDeserializer<>(schemaRegistryClient));
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, UserRegistrationTest> kafkaListenerContainerFactory(SchemaRegistryClient schemaRegistryClient) {
ConcurrentKafkaListenerContainerFactory<String, UserRegistrationTest> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory(schemaRegistryClient));
return factory;
}
}
Producer Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
@Data
@Builder
@Getter
public class UserRegistrationTest {
private String userId;
private String email;
private String name;
}
@Service
@RequiredArgsConstructor
public class KafkaProducer {
private final SchemaRegistryClient schemaRegistryClient;
private final KafkaTemplate<String, UserRegistrationTest> kafkaTemplate;
public void sendMessage(UserRegistrationTest userRegistrationTest) throws RestClientException, IOException {
schemaRegistryClient.reset();
int version = schemaRegistryClient.getLatestSchemaMetadata(TOPIC+"-value").getVersion();
System.out.println("Version: " + version);
kafkaTemplate.send(TOPIC, userRegistrationTest);
System.out.println("Message sent: " + userRegistrationTest);
}
}
@RestController
@RequiredArgsConstructor
@RequestMapping("/kafka")
public class KafkaController {
private final KafkaProducer kafkaProducer;
@PostMapping("/publish")
public String publishMessage(@RequestBody UserRegistrationTest userRegistrationTest) throws RestClientException, IOException {
kafkaProducer.sendMessage(userRegistrationTest);
return "Message published: " + userRegistrationTest.toString();
}
}
Consumer Example
1
2
3
4
5
6
7
8
9
@Service
@RequiredArgsConstructor
public class KafkaConsumer {
@KafkaListener(topics = TOPIC)
public void consume(String message) {
System.out.println("Message received: " + message);
}
}
Publish message to Kafka topic
1
2
3
4
5
6
7
8
curl --request POST \
--url http://localhost:8100/kafka/publish \
--header 'Content-Type: application/json' \
--header 'User-Agent: insomnia/10.2.0' \
--data '{
"userId": "pravin",
"email": "pravin@pravin.dev"
}'
Best Practices and Considerations
Schema Evolution Guidelines
- Minimize breaking changes
- Use default values for new required fields
- Test compatibility before deploying
- Monitor schema changes
Potential Challenges
- Managing complex schema evolutions
- Ensuring backward/forward compatibility
- Performance overhead of schema validation
Conclusion
Kafka Schema Registry with JSON Schema provides a robust solution for managing data structures in distributed systems. By carefully implementing schema evolution strategies, developers can create flexible, maintainable, and scalable data streaming architectures.
Key Takeaways
- Centralize schema management
- Implement careful evolution strategies
- Utilize default values
- Continuously test and validate schemas